
Set 컬렉션 클래스란?
Set 인터페이스를 구현안 모든 Set 컬렉션 클래스는 다음과 같은 특징을 가집니다.
- 요소의 저장 순서를 유지하지 않습니다.
- 같은 요소의 중복 저장을 허용하지 않습니다.
Set 인터페이스에서 공통적으로 사용 가능한 메서드는 다음과 같습니다.
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | boolean | add(Object o) | 객체를 추가하고, 성공하면 true를, 중복 객체면 false를 반환. |
| 객체 검색 | boolean | contains(Object o) | 객체가 Set에 존재하는지 확인 |
| boolean | isEmpty() | Set이 비어있는지 확인 | |
| Iterator | Iterator() | 저장된 객체를 하나씩 읽어오는 반복자를 리턴 | |
| int | size() | 저장되어 있는 전체 객체의 수 리턴 | |
| 객체 삭제 | void | clear() | Set에 저장되어져 있는 모든 객체를 삭제 |
| boolean | remove() | 주어진 객체를 삭제 |
Set 인터페이스는 Collection 인터페이스를 상속받으므로, Collection 인터페이스에서 정의한 메서드도 모두 사용할 수 있습니다.
대표적인 Set 컬렉션 클래스에 속하는 클래스는 아래와 같습니다.
- HashSet<E>
- TreeSet <E>
HashSet <E> 클래스
HashSet 클래스는 Set 컬렉션 클래스에서 가장 많이 사용되는 클래스 중 하나입니다.
JDK 1.2부터 제공된 HashSet 클래스는 해시 알고리즘(hash algorithm)을 사용하여 검색 속도가 매우 빠릅니다.
이러한 HashSet 클래스는 내부적으로 hashMap 인스턴스를 이용하여 요소를 저장합니다.
hashSet 클래스는 Set 인터페이스를 구현하므로, 요소를 순서에 상관없이 저장하고 중복된 값을 저장하지 않습니다.
만약 요소의 저장 순서를 유지해야 한다면 LinkedHashSet 클래스를 사용하면 됩니다.
다음 예제를 통하여 HashSet 메서드를 이욯하여 집합을 생성하고 조작하는 모습을 보도록 하겠습니다
import java.util.HashSet;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
HashSet<String> hs1 = new HashSet<>();
HashSet<String> hs2 = new HashSet<>();
//add() 메서드를 이용한 요소 저장
hs1.add("사과");
hs1.add("딸기");
System.out.println(hs1.add("수박"));
System.out.println(hs1.add("수박"));// 중복된 요소 저장
//요소 출력
for (String e : hs1){
System.out.print(e + " ");
}
System.out.println("");
// add() 메서드를 이용한 요소 저장
hs2.add("딸기");
hs2.add("수박");
hs2.add("사과");
// iterator() 메서드를 이용한 요소의 출력
Iterator<String> it = hs2.iterator();
while(it.hasNext()){
System.out.print(it.next() + " ");
}
System.out.println("");
// remove() 메서드를 이용한 요소 삭제
hs2.remove("딸기");
// size() 메서드를 이용한 요소의 총 개수
System.out.println("객체의 개수는? :" + hs2.size());
}
}
// 출력 결과
true
false
수박 사과 딸기
수박 사과 딸기
객체의 개수는? :2위의 예제코드를 보면 요소의 저장 순서를 바꿔도 저장되는 순서에는 영향을 끼칠 수 없습니다.
이때 해당 HashSet에 이미 존재하는 요소인지 파악하기 위해서는 내부적으로 다음과 같은 과정을 거치게 됩니다.
- 해당 요소에서 hashCode() 메서드를 호출하여 반환된 해시값으로 검색할 범위를 결정
- 해당 범위 내의 요소들을 equals() 메서드로 비교
따라서 HashSet에서 add() 메서드를 사용하여 중복 없이 새로운 요소를 추가하기 위해서는 hashCode()와 equals() 메서드를 상황에 맞게 오버라이딩해야 합니다.
해시 알고리즘(hash algorithm)
해시 알고리즘(hash algorithm)이란 해시 함수 (hash function)을 이용하여 데이터를 테이블(hash table(에 저장하고, 그것을 다시 검색하는 알고리즘입니다.
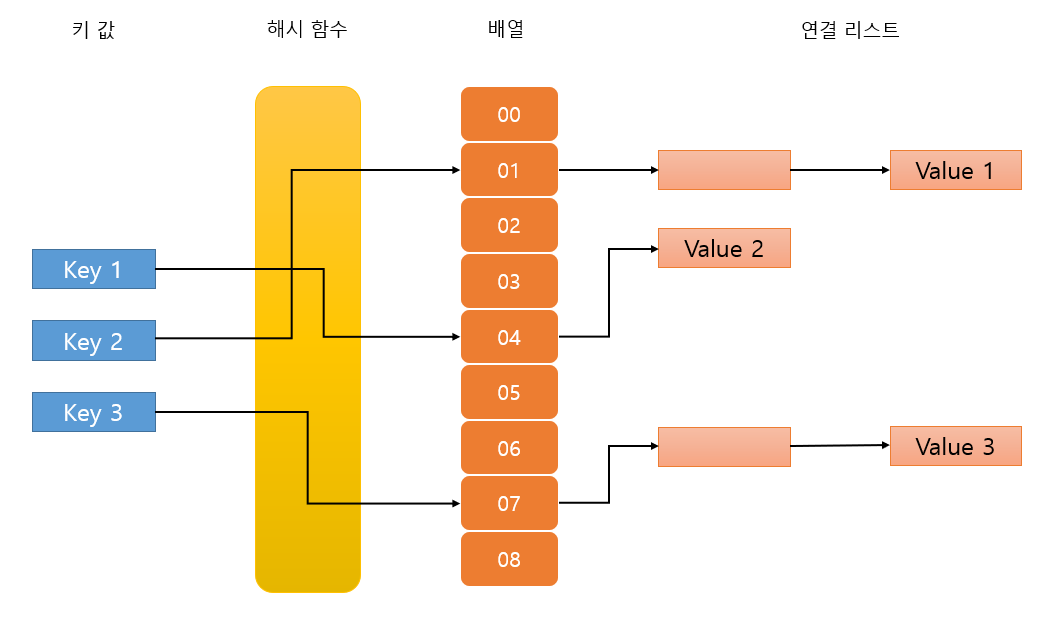
자바에서 해시 알고리즘을 이용한 자료 구조는 위의 그림과 같이 배열과 연결 리스트로 구현됩니다.
저장할 데이터의 키 값을 해시 함수에 넣어 반환되는 값으로 배열의 인덱스를 구합니다.
그리고 해당 인덱스에 저장된 연결 리스트에 데이터를 저장하게 됩니다.
TreeSet <E> 클래스
TreeSet 컬렉션 클래스는 데이터가 정렬된 상태로 저장되는 이진 검색 트리(binary search tree)의 형태로 요소를 저장합니다.
이진 검색 트리는 데이터를 추가하거나 제거하는 등의 기본 동작 시간이 매우 빠릅니다.
TreeSet 클래스는 Set 인터페이스를 구현하므로, 요소를 순서에 상관없이 저장하고 중복된 값은 저장하지 않습니다.
다음 예제 코드와 함께 확인해 보도록 하겠습니다.
import java.util.Iterator;
import java.util.TreeSet;
public class Main {
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<>();
// add() 메서드를 이용한 요소의 저장
ts.add(30);
ts.add(40);
ts.add(20);
ts.add(10);
// Enhanced for 문과 get() 메서드를 이용한 요소 출력
for(int e: ts){
System.out.print(e + " ");
}
System.out.println("");
// remove() 메서드를 이용한 요소 제거
ts.remove(40);
//iterator() 메서드를 이용한 요소 출력
Iterator<Integer> it = ts.iterator();
while(it.hasNext()){
System.out.print(it.next() + " ");
}
System.out.println("");
// size() 메서드를 이용한 요소의 총 개수 출력
System.out.println("이진 검색 트리의 크기: " + ts.size());
// subSet() 메서드를 이용한 부분 집합 출력
System.out.println((ts.subSet(10,20)));
System.out.println(ts.subSet(10,false,30,true));
}
}
// 출력 결과
10 20 30 40
10 20 30
이진 검색 트리의 크기: 3
[10]
[20, 30]위의 예제처럼 TreeSet 인스턴스에 저장되는 요소들은 모두 정렬이 된 상태로 저장됩니다.
Reference
'JAVA' 카테고리의 다른 글
| [JAVA] 컬렉션 프레임워크(Collection Framework) - Stack,Queue (5) (0) | 2023.03.11 |
|---|---|
| [JAVA] 컬렉션 프레임워크(Collection Framework) - Map <K,V> (4) (2) | 2023.03.10 |
| [JAVA] 컬렉션 프레임워크(Collection Framework) - List <E> (2) (0) | 2023.03.09 |
| [JAVA] 컬렉션 프레임워크(Collection Framework) (1) (0) | 2023.03.09 |
| [JAVA] 예외 처리(Exception Handling) (0) | 2023.03.08 |



